億級用戶時代 分布式數據存儲的架構演進與實踐
在數字化轉型的浪潮中,如何為億級用戶提供穩定、高效且可擴展的數據存儲服務,已成為眾多互聯網企業面臨的核心挑戰。王知無在其《從Java到大數據之路》系列博客中,深入探討了這一領域的解決方案,為我們揭示了從傳統架構向分布式存儲演進的技術脈絡與實踐智慧。
一、 億級用戶帶來的數據存儲挑戰
當用戶規模突破億級,傳統的單體數據庫或簡單的主從架構往往不堪重負。數據量呈指數級增長(海量性),高并發讀寫請求(高并發性),對服務可用性與數據一致性要求極高(高可用與強一致),并且業務需求快速變化要求架構具備彈性伸縮能力(可擴展性)。這些挑戰迫使技術架構必須進行根本性的革新。
二、 分布式數據存儲的核心設計思想
應對上述挑戰,現代分布式存儲系統普遍遵循幾個核心設計原則:
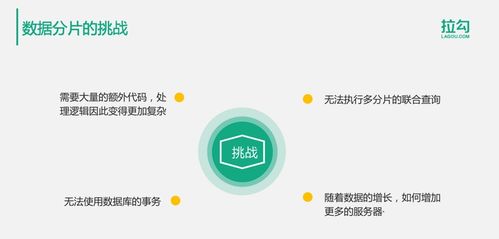
- 分而治之(Sharding/Partitioning):將龐大的數據集水平拆分到多個數據庫實例或節點上,分散存儲與計算壓力。這要求設計良好的分片鍵(Shard Key)以保證數據分布均勻與查詢效率。
- 冗余復制(Replication):同一份數據在多個節點上保存副本,是保證高可用和容錯的基礎。根據一致性要求的不同,有主從復制、多主復制、無中心復制(如Paxos、Raft共識算法)等模式。
- 彈性伸縮(Elastic Scalability):系統應能根據負載動態增加或減少節點,且對應用透明。這涉及數據的自動重平衡(Rebalancing)技術。
- 最終一致性與BASE理論:在追求高性能和高可用的場景下,可以適當放寬對強一致性的要求,采用最終一致性模型。BASE(Basically Available, Soft state, Eventually consistent)理論是這類系統的基石。
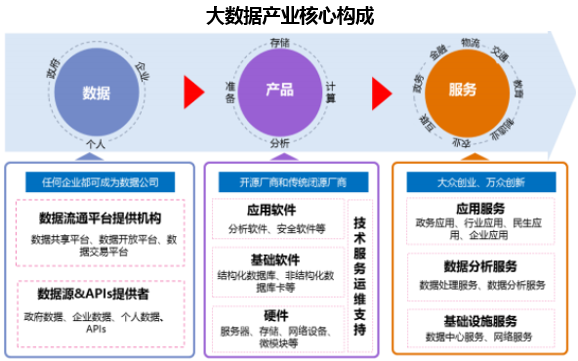
三、 主流分布式存儲解決方案選型
根據數據結構與訪問模式的不同,解決方案大致分為幾類:
- 分布式關系型數據庫:如Google Spanner(及其開源實現如TiDB、CockroachDB),在提供SQL接口和ACID事務的實現了全球級的分布與水平擴展。
- 分布式鍵值(Key-Value)存儲:如Redis Cluster、etcd,適用于緩存、會話存儲和配置管理等高性能場景。
- 分布式文檔/列族存儲:如MongoDB、Cassandra、HBase,擅長處理半結構化數據,具備靈活的模式和良好的水平擴展能力。
- 分布式對象存儲:如AWS S3、MinIO,專為存儲圖片、視頻、日志等海量非結構化數據設計。
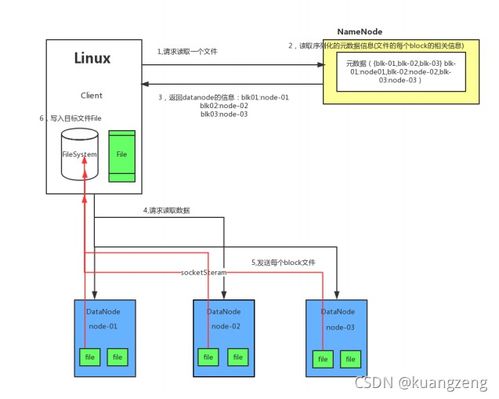
- 分布式文件系統:如HDFS、Ceph,為大數據分析(如Hadoop/Spark生態)提供底層存儲支撐。
選型時需綜合考量數據模型、一致性要求、讀寫模式、延遲敏感度以及運維成本。
四、 從Java應用到大數據體系的架構融合
正如王知無在博客中梳理的路徑,現代Java后端開發者必須理解大數據存儲生態。典型的融合架構是“分層存儲”:
- 在線事務層(OLTP):使用分布式關系數據庫或文檔數據庫處理核心業務交易,保證實時性和一致性。
- 在線分析層(OLAP):通過數據同步工具(如Canal、Debezium)將事務層數據實時或準實時導入到像ClickHouse、Doris或大數據平臺(Hive/Spark on HDFS)中,供復雜分析與報表使用。
- 數據湖與流處理層:使用Kafka作為實時數據流總線,將日志、事件數據匯入數據湖(如Iceberg、Hudi on HDFS/S3),并通過Flink/Spark Streaming進行實時處理,形成數據閉環。
五、 數據處理與存儲支持服務的關鍵實踐
構建穩定的支持服務,離不開以下實踐:
- 監控與告警:對集群健康度、性能指標(QPS、延遲、吞吐)、容量進行全方位監控。
- 自動化運維:利用Ansible、Kubernetes Operators等實現集群的自動化部署、擴縮容與升級。
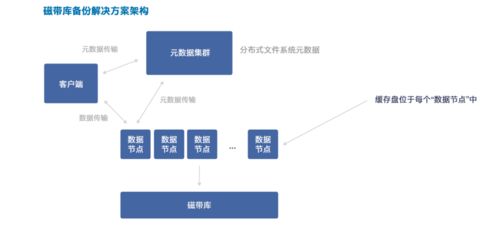
- 備份與容災:制定跨機房、跨地域的數據備份與災難恢復策略,定期進行容災演練。
- 成本優化:根據數據冷熱特性實施分層存儲(如S3標準存儲與冰川存儲),清理無效數據,優化資源使用。
- 安全與治理:實施細粒度的訪問控制、數據加密(傳輸中與靜態)和審計日志,滿足合規要求。
服務于億級用戶的分布式數據存儲系統,沒有一成不變的“銀彈”。它是一條持續演進的道路,需要根據業務特性,在一致性、可用性、分區容錯性(CAP定理)之間做出權衡,并靈活組合各類技術組件。王知無的分享提示我們,從扎實的Java開發走向廣闊的大數據架構,核心在于掌握分布式系統的基本原理,并保持對新技術棧的開放與實踐精神。只有這樣,才能構建出真正支撐業務騰飛的數據基石。
如若轉載,請注明出處:http://www.guakaowang.com.cn/product/22.html
更新時間:2026-05-28 19:56:09